 This
paper is adapted from a presentation at 'A Decade of Power', the third annual
conference of the Belgium-Luxembourg SGML Users Group, held in Brussels 30-31
October 1996.
This
paper is adapted from a presentation at 'A Decade of Power', the third annual
conference of the Belgium-Luxembourg SGML Users Group, held in Brussels 30-31
October 1996.| Computers & Texts No. 15 |
Table of
Contents |
August 1997 |
Lou Burnard
Humanities Computing Unit
University of Oxford
lou.burnard@oucs.ox.ac.uk
This
paper is adapted from a presentation at 'A Decade of Power', the third annual
conference of the Belgium-Luxembourg SGML Users Group, held in Brussels 30-31
October 1996.
Readers may not need to be reminded what SGML is (Standard Generalized Markup Language: the international standard for structured document interchange, ISO 8879 (1986) if you have forgotten). It might also be helpful to remind you of what exactly the Web is, particularly now that URLs and cyberspace have become an established part of journalism, junk capitalism, and other components of life as we know it. The best definition of the World Wide Web I have come across was from Dave Raggett, who pointed out that the Web has exactly three components:
Given the immense success of the World Wide Web, it is not unreasonable to ask what more anyone could reasonably require. As they say: 'If it ain't broke, why fix it?' I will begin by rehearsing some of the things that have proved to be wrong with HTML (Hypertext MarkUp Language) as an interchange format, if we compare it with other general-purpose Document Type Definitions. At the risk of reiterating something rather obvious, the HTML DTD tries to cater for the immense and glorious variety of structures that exist in electronic resources by taking the line of least resistance, and pretending that documents have no structure at all. HTML's permissiveness makes it difficult or impossible to do many of the things for which we go to the trouble of making information digitally accessible. Specifically, it is hard to:
This last difficulty highlights a further major case of drawbacks resulting from the nature of the HTML document type definition: it is semantically impoverished, and it is presentation-oriented. By semantically impoverished, I do not simply mean that HTML lacks any way of distinguishing between data such a person's name, and a section of prose; indeed it provides no way of marking up any kind of textual object other than headings, lists, and (arguably) paragraphs. By presentation-oriented, I mean that HTML compensates for this serious lack only by allowing for an increasingly complex range of ways of specifying the way that a span of text should be rendered, rather than any way of specifying what kind of an object the span is. The relationship between what an object is, and how it is rendered, has exercised much theoretical debate, which I will not rehearse here, but one key fact remains: all SGML systems are predicated on the assumption that markup is introduced in ordered to distinguish semantic categories of various kinds, the meaning of which are rarely limited to how they should be rendered. On the contrary, the assumption is that they may be rendered in many different ways by different applications. This is hard, or impossible, with HTML.
This focus on bold and italic, on headings, and bulletted items, would matter less if HTML were extensible (or if its host environment allowed for its substitution by a more expressive DTD). It would also matter less if HTML were even adequate as a data format for large-scale commercial publishing. But neither of these is the case. If we compare even the best of HTML tools with even the worst of generic SGML tools, we note that the hardwiring of the HTML tool to a particular set of tags (with or without proprietary extensions) make it impossible for the user to extend the tool's functionality in any way. By separating out formatting and structuring issues, even the humblest of SGML tools allows the user to retain complete control over the data.
The advent of HTML stylesheets appears to address this limitation, by extending the choice of formatting options available to HTML tools in a number of useful ways. However, the stylesheet mechanism as so far defined lacks several aspects of output control typically supported by generic SGML tools. It cannot for example be used as means of re-ordering the components of a document, or of selecting parts of it in some application-specific manner Ñ both of which are perfectly reasonable requirements in mature technical publishing environments, and both of which are easily achieved by current generic SGML document processing systems.
Leaving aside the economic, political, and sociological answers to this question, there is at least one important respect in which I have rather undersold the case for HTML in the discussion so far. A very large proportion of the material on the Web is ephemeral by design: its purpose is to make an impact in the 'here and now' - whether to sell a product, advertise a venue, or just make a splash. There is no reason, therefore, why its producers should treat it any more carefully than we treat paper ephemera. The difficulty arises from the fact that HTML has to be used whether we are trying to encode a monumental reference work of long term value, or to advertise the merits of the latest soft drink.
Even for documents which have a long-term value, HTML really only suffers when compared to generic (i.e. extensible) SGML from an author's or publisher's standpoint. Readers, after all, do not care whether the display on their screen came from a state-of-the-art object-oriented database, from a postscript file, or by the careful application of black magic, as long as it looks nice. But many (if not most) readers would like to be author and publishers too - that empowerment is after all what the Web was supposed to offer us. Moreover, the quality of service delivered by a network publication surely is not solely measured by the dramatic presentational effects it uses; sooner or later the reliability and sophistication of its content become a marketing advantage. Given this interdependence, it may be helpful to re-assess the usefulness of HTML on either side of the client/server divide.
As a server format, HTML has some fairly evident drawbacks. Despite low start-up costs, any serious long term investment in service provision based on HTML documents as the primary storage method is unlikely to be wise. The headaches of maintaining consistent links in any moderately dynamic collection simply do not bear thinking about. A hybrid system, where document management and control is carried out by a database system, linked into a static collection of HTML documents is possible, but will require as much investment as would a stand-alone native SGML document system, without any of the intrinsic benefits.
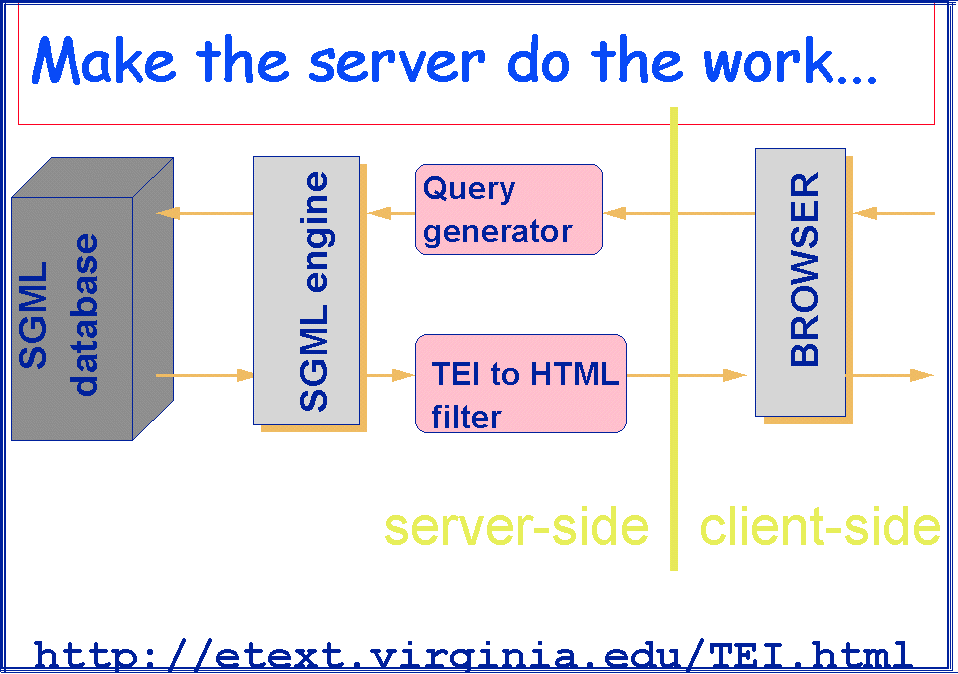 |
Fig. 1.
On the client side, the balance is in favour of HTML:
For the moment, it seems reasonable therefore to try to get the best of both worlds, by using SGML on the server side, with HTML as a delivery vehicle (see fig. 1). Not only does this seem reasonable, it is indeed what a number of serious electronic publishers are already doing.
However, SGML-to-HTML servers tend to be complex, expensive, and CPU-intensive database applications which only large corporations can afford. Hybrid clients like Panorama provide only half the functionality needed, at twice the cost. We clearly need to see a new breed of software before we can deliver on some of the promises of the world of structured documents. However sophisticated our servers, existing user agents will remain unable to take full advantage of the potential richness of the SGML documents already existing in the world, still less those which are being created, so long as they persist in regarding anything beyond HTML as outside their preserve.
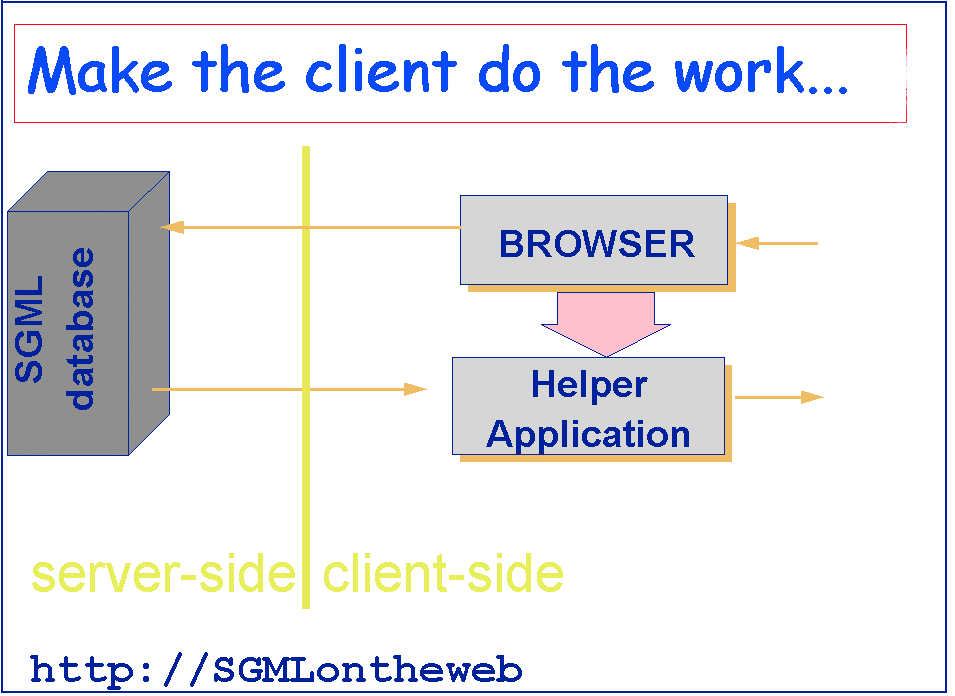 |
Fig. 2.
What is required for future Web user agents to be able to receive and process any SGML object in the way that they are currently able only to handle HTML? There are two halves to the answer. Firstly, servers providing SGML objects need to deliver along with them some kind of wrapper indicating the document's structural description (DTD) and stylesheet information defining its rendition. Secondly, clients must be able to unpack this package of information correctly, delegating the actual processing of the document to appropriate subcomponents responsible for parsing, constructing, and rendering it. This approach necessitates the creation of a number of specifications, key elements of which are listed below:
Work on specifying all these components in the context of the Web is already well advanced, as a result of substantial discussion and serious work within the appropriate expert communities, most notably within working groups of the W3C Consortium. For an overview of the current situation, see http://www.w3.org/MarkUp/SGML/. I will conclude with a few remarks on two of these only: those concerned with document rendering, and the need for a simplified SGML.
At present, each SGML browser has its own proprietary SGML stylesheet language. No content provider could reasonably be expected to design and supply a different stylesheet for every possible target. Some kind of generic stylesheet mechanism is thus clearly essential. At present two candidates for this mechanism present themselves: the cascading style sheet mechanism, and the ISO standard Document Style Semantics and Specification Language (DSSSL). The advantage of the latter is not simply that it has emerged from the standards community after nearly a decade of very hard work, nor that real implementations of it are now freely available. It is simply that cascading styles do not have enough power for the job.
As currently defined, the Cascading Style Sheets lack the concept of a parse tree essential to correct processing of an SGML document. Consequently:
Because there are no programming language features, a CSS style sheet lacks decision structures, modularization, variables, and any way of doing arithmetic calculation. As a way of improving the way that HTML texts are rendered on screen (provided that they are in Western alphabets), it is adequate, but as a generic solution to the problem of rendering SGML documents, it lacks a lot.
The key advantage of DSSSL lies in its modular design. It integrates three key components (see fig. 3):
A full description of DSSSL is beyond the scope of this paper: a good description of the DSSSL-Online subset, and a number of other tutorials are freely available from James Clark's DSSSL pages (at http://www.jclark.com/dsssl) and elsewhere. Its key features for the present argument are as follows:
Consequently, anything which can be expressed in the SGML definitions underlying a document repository can be used in the creation of the view of it which a particular client sees. A user agent with a suitable DSSSL specification can handle whatever SGML structures are obtained from a true SGML server, re-ordering, selecting, combining, and rendering SGML elements according to a formally complete specification.
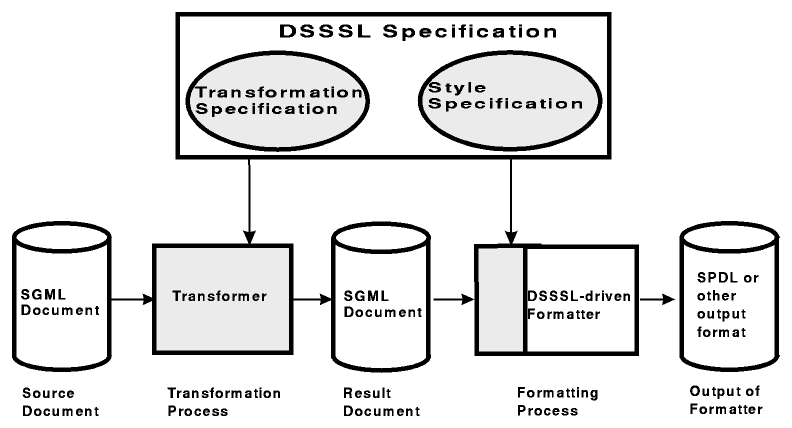 |
Fig. 3.
The big question in all this remains: if SGML is so great, why has it not taken over the world already? Amongst (varyingly sensible) answers to this which I will not pursue further are the argument that it has, at least as far as serious document management is concerned; the argument that taking over the world is not the object of the exercise since SGML vendors and advocates are culpably uninterested in developing software for the common man or woman; and the argument that there is an inherent contradiction between the goals of SGML and the goals of the politico-industrial-military complex which currently runs the data processing industry. However, the question requires an answer, and perhaps the development of XML will provide it.
XML (eXtensible Markup Language) is a new activity of the W3C SGML work group. Its goal is to define a leaner, simpler, subset of the SGML metalanguage, better suited for use on the Internet, able to support a wide variety of applications, and with a concise formal design. Over a number of months, a select group of about fifty SGML experts have been debating, with all the vigour and obsessive attention to detail so characteristic of the breed, exactly which parts of the SGML elephant should be cast to the wolves following the sledge on its way towards the promised land of XML implementability.
Amongst topics discussed I list only a few to give some flavour of the radical nature of what is being proposed:
Working Papers on XML Syntax (revised June 1997) and XML Linking (April 1997) have been published by the W3 Consortium and can be accessed from http://www.w3.org/XML. Publication of a complete XML specification will, it is hoped, remove the last obstacle to the emergence of a new breed of truly SGML-aware user agents on the Web, able to take full advantage of the true potential of the information revolution that began ten years ago with the publication of ISO 8879.
A full version of this paper is available at http://users.ox.ac.uk/~lou/Belux/
[Table of Contents] [Letter to the Editor]
Computers & Texts 15 (1997), p. 12 Not to be republished in any form
without the author's permission.
HTML Author: Sarah Porter
Document
Created: 8 September 1997
Document Modified:
The
URL of this document is
http://info.ox.ac.uk/ctitext/publish/comtxt/ct15/burnard.html