Data Analysis for Neuroscientists V:
Regression


Regression: How to predict one variable from another variable
Last week looked at how to test for differences between sets of data points - eg between the heights of alleged Vikings and bone fide Shetlanders.
This week we will consider a complementary question:
How can the value of one variable be predicted from the value of another variable?
For example:
- How can the firing rate of a retinal receptor cell be predicted from the intensity of light falling on it?
- How can the activity of a brain region (measured with fMRI) be predicted from the difficulty of the arithmetic problem being solved at the time?
- How can a participant's choices in a gambling task be predicted based on the magnitude of the expected payout?
All of these questions can be addressed by fitting regression models.
Galton's measurements: child vs. midparentIn the early 20th Century, Galton set up his "Anthropometric Laboratory" in which he measured a whole set of characteristics of individuals (including, notably, collecting some of the first reaction time measurements) He got a lot of data and people actually paid to take part in his study (see handbill above)! One of Galton's observations was that children's height is similar to the average of their parents' heights (the 'midparent height')
? |

|
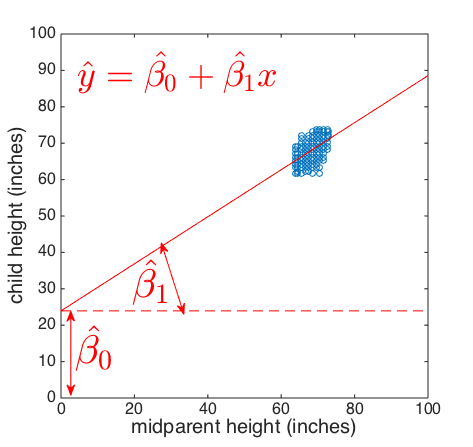
Fitting the regression lineThe red line on the graph above is a regression line, indicating the best fit linear relationship between:
The simplest case is that the predicted value of the dependent variable y is a linear function of the independent variable x We tend to use slightly different notation:
.... where is the estimated y-intercept and is the estimated gradient. We can find the values of β0 and β1 analytically (using an equation) but we are not going to go into the mechanics of this today. Instead we will fit the regression line using the Matlab function glmfit |
|
The Residuals
The difference between the fitted data and the actual data, - y, are called the residuals
When fitting the regression line we chose values of and to minimise the square of the residuals (this is called "ordinary least squares" regression, or OLS).
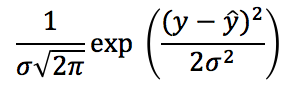
We can find the residuals for our regression by working out the predicted value of child height y, that is, , for each value of midparent height x in our data set...
?
... and then doing - y
?
Plot a histogram of the residuals. Are they normally distributed?
?
Testing, testing
The regression line for the data we just generated looks pretty convincing. But how can we test if the relationship is statistically significant?
To test whether there is a significant relationship between x and y, we want to test whether the slope is significantly different to zero. There are two factors that should influence our opinion about this:
- What is the gradient of the slope? If the slope is very flat, we should be more likely to believe that the real relationship could be zero than if the slope is steep.
- How sure are we about the gradient of the slope?

- Our original data
- More spread in y --> more uncertainty about slope
- Less spread in x --> more uncertainty about slope
- Fewer data points --> more uncertainty about slope
The equation for the standard error (SE) of the regression slope captures all of these factors:
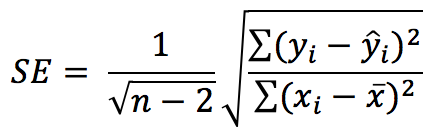
In other words -
- For each data point yi, the further it is from the predicted value , the higher the SE
- For each data point xi, the further it is from the mean value , the lower the SE
- The more data points we have (high n), the lower the SE
The significance of the regression slope can then be calculated simply by defining the t-statistic:
| t = β1/SE |
And comparing it against the t-distribution with (n-2) degrees of freedom.
Exercise: significance of the regression slope
To calculate the t-value for our regression:
- Work out Σ(yi - )2 using the fitted values and values of y (child height)
- Work out Σ(xi -
?
Then we get the p-value by comparing to the t(n-2) distribution
?
Exercise: Standard error of the regression slope
What does it mean to talk about the Standard Error for a slope, actually?
Last week, we looked at the Standard Error of the Mean (SEM) for samples:
- The SEM is the standard deviation of the distribution of the sample mean.
- So when we...
- generated lots of samples (say, samples of 10 Normal-distributed random numbers)
- found the mean of each sample,
- plotted a histogram of those means
...the spread of that histogram was what was captured by the SEM.
In other words, the SEM for the sample tells us about the spread of our estimate of the sample mean - which is important if we want to say whether the difference between the sample mean and some reference value (like a population mean, or zero) could have arisen due to chance.
The SE of the regression slope, similarly, tells us about a distribution of possible slopes that we might have got, if we had sampled different data from the same distribution
To get a feel for this, let's try grabbing smaller samples from our 'population' of 928 children and running the regression on them, then plotting all the resulting regression lines on the same graph to see how the slope varies:
- Can you make a script with a for loop that:
- generates 100 samples of size 50 from the population
- finds the regression coefficients for each sample
- saves them into a matrix
- plots the relevant regression lines
- It may help to look back at last week's work
- Now do it again for samples of size 10.
- Did the distribution of slopes gets smaller?
- How should the standard error have changed (look at the formula)
?
Take home message
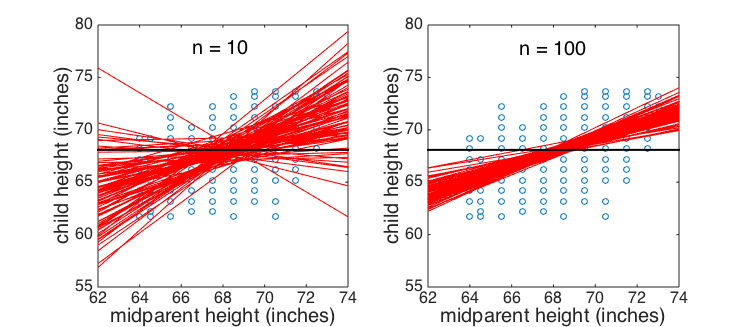
Regression slopes based on samples of 10 and 100 subjects from the same subject population
Although the statistic we are looking at is different from last week (a sample regression slope rather than a sample mean), to work out whether an effect is significant, we are considering how frequently an event would happen (in this case, how frequently some value for the regression slope would be above zero) if we repeated the experiment lots of times.
Further Exercises
Look back at the Oxford Weather data from the 2nd class. There is clearly a relationship between temperature and month - but it is not a straight line. How can we fit this with regression?
HINT: it looks sinusiodal to me...